JavaScript を使って画面上の要素を入れ替えたとき、スクロール位置が勝手に動いて画面がカクつくという現象に遭遇しました。調査して分かったことをまとめます。
まずはデモをご覧ください
todays-mitsui.github.io
カラフルな <div> が並んでいて、右上のボタンを押すとすぐ上の要素と位置が入れ替わるデモを作りました。
 ボタンを押すとすぐ上の要素と入れ替わる
ボタンを押すとすぐ上の要素と入れ替わる
ここまではなんの変哲もありません。ところが、まったく同じコードでも要素が大きくなると違う挙動になります。
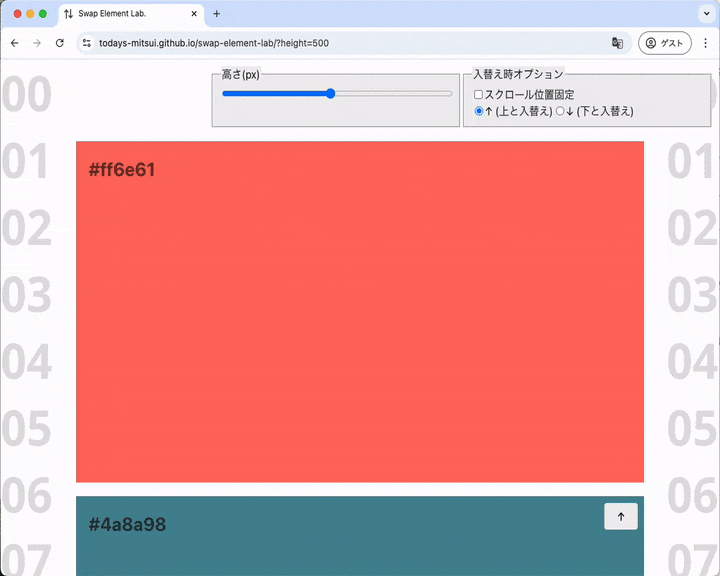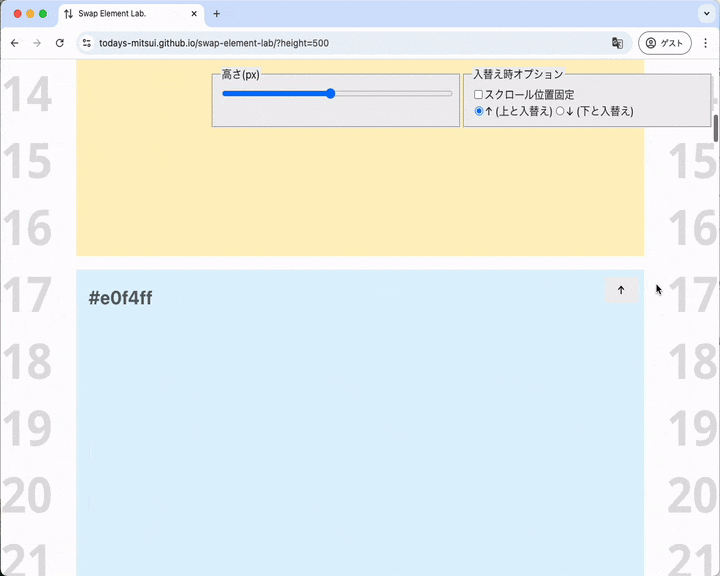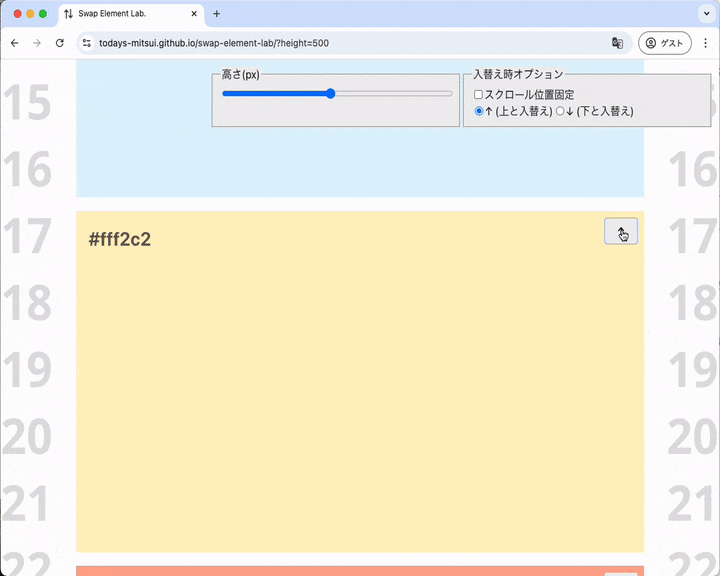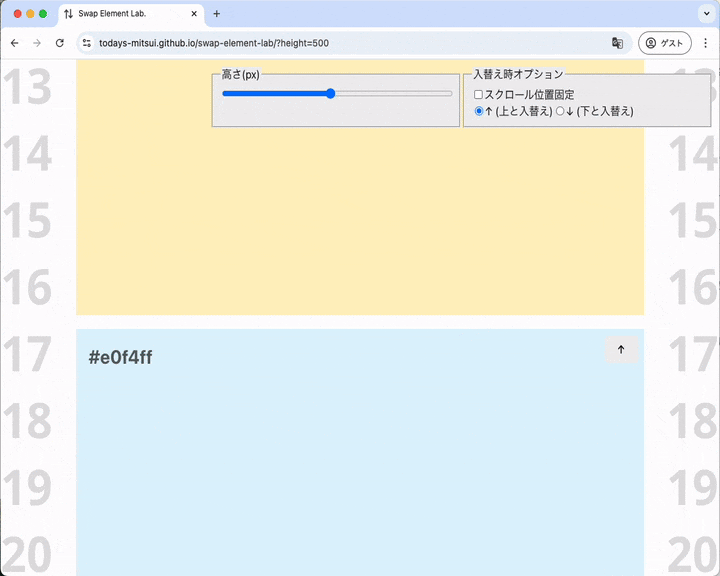 すぐ上の要素と入れ替わる、と同時にスクロール位置がシフトする
すぐ上の要素と入れ替わる、と同時にスクロール位置がシフトする
ボタンを押すと同時にスクロール位置がシフトしているのが分かります。背景に敷いてある「01, 02, 03, 04, ...」の数字に着目すると分かりやすいかも。
この記事ではどのような条件でスクロールシフトするのか調べてみます。
目次
3行まとめ
- 要素の高さは無関係
- 移動した後の要素の上端がビューポートからはみ出すか、ビューポートの上端に近いとスクロールが追従する
- すぐ下の要素と入れ替える処理ではもっと不可解な挙動になる
- CSS の overflow-anchor プロパティ で制御できる
解決策だけ見たい人は スクロール調整 (スクロールアンカリング) を無効にする方法 を見てください。
デモのすべてのコードは GitHub に置いています。 → https://github.com/todays-mitsui/swap-element-lab
要素入れ替えのコード
今回のデモは React で組んでいます。要素のレンダリングはのような感じです。
function App() {
const [colors, setColors] = useState(['#ff6e61', '#4a8a98', '#fff2c2', ...]);
return (
{colors.map((color, index) => (
div style={{ backgroundColor: color }} key={color}
h3{color}h3
button type="button"↑button
div
))}
);
}
要素に背景色 (background-color) をつけているのは入れ替わりをわかりやすくするためで、スクロール位置がずれる挙動には直接関係ありません。
ここに要素入れ替えの処理を追加します。
const handleSwap = (i: number) => {
const newColors = [...colors];
[newColors[i], newColors[i-1]] = [newColors[i-1], newColors[i]];
setColors(newColors);
};
素朴に i 番目 と i-1 番目 を入れ替えてから setColors しているだけです。
二つを合わせるとこんな感じになります。
function App() {
const [colors, setColors] = useState(['#ff6e61', '#4a8a98', '#fff2c2', ...]);
const handleSwap = (i: number) => {
const newColors = [...colors];
[newColors[i], newColors[i-1]] = [newColors[i-1], newColors[i]];
setColors(newColors);
};
return (
{colors.map((color, index) => (
div style={{ backgroundColor: color }} key={color}
h3{color}h3
button type="button" onClick={() => handleSwap(index)}↑button
div
))}
);
}
入れ替え後の要素の top の位置が条件になっているみたい
いろいろと実験してみました。入れ替え後の要素の上端 (top) がビューポートに対してどの位置にあるかによってレイアウトシフトが 起こる/起こらない が変わるようです。
要素が高くてもスクロールシフトが起こらないことがある
要素が高くてもスクロールシフトが起こらない場合があります。入れ替え後に要素がビューポートにおさまる位置にあればスクロールシフトは起こりません。
https://todays-mitsui.github.io/swap-element-lab/?height=500&scroll=2100
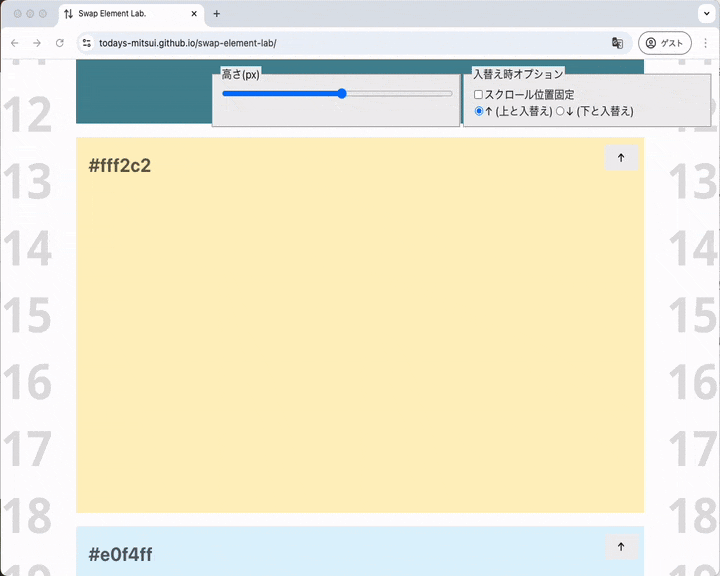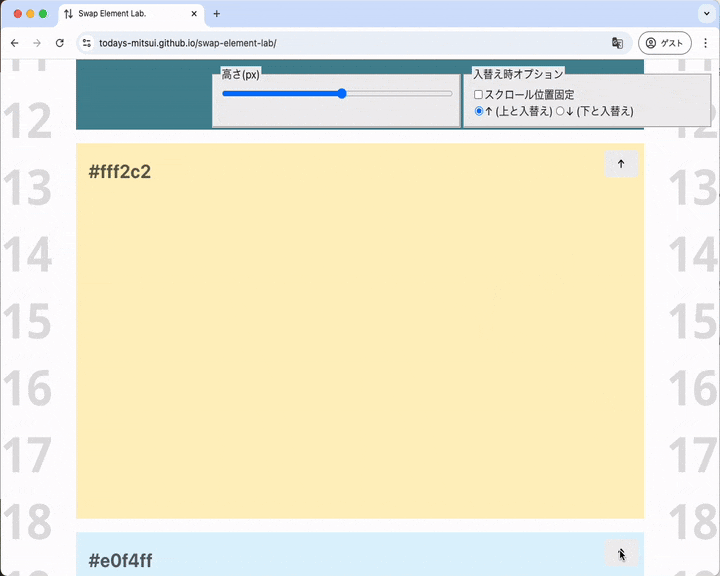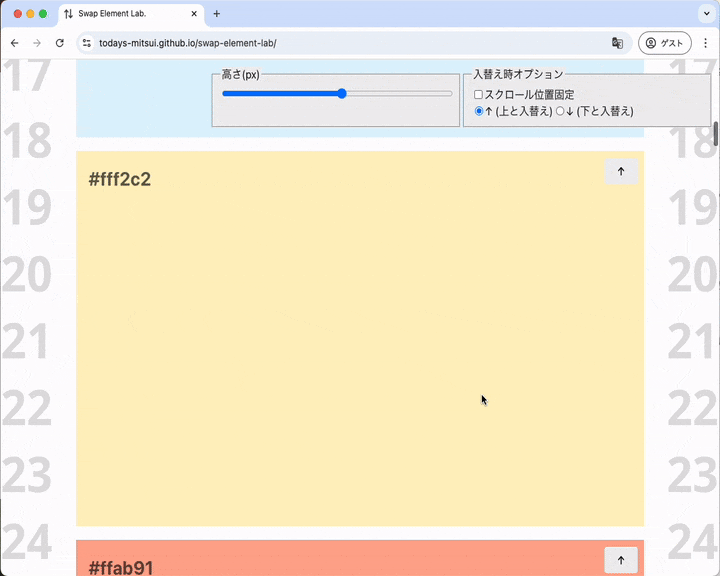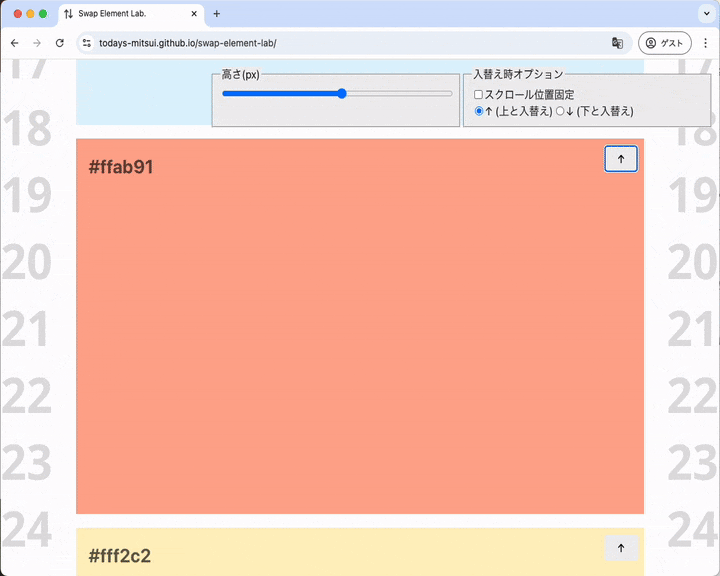 ビューポートの下のほうにある要素を入れ替え、ビューポートの真ん中に持ってくる
ビューポートの下のほうにある要素を入れ替え、ビューポートの真ん中に持ってくる
要素が低くてもスクロールシフトが起こることがある
逆に、要素が低くても入れ替え後にビューポートの上端付近に来る場合にはレイアウトシフトが起こります。
入れ替え後にも要素が確実にビューポートに入るように調整される、と考えると分かりやすいです。
 ビューポート上端に近いと、ビューポートの中ほどにスクロール調整される
ビューポート上端に近いと、ビューポートの中ほどにスクロール調整される
ここまでのまとめ
- 入れ替え後にビューポートにおさまっていればスクロールシフトはおこらない
- 入れ替え後にビューポートからはみ出しているか端すぎればスクロール位置が調整される
このように考えると理解しやすいですね。
「下の要素と入れ替える」という動作にするともっと不可解なことが起こる
先ほどまではボタン押下で上の要素と入れ替えるという動作のもと実験していました。これをボタン押下で 下の要素 と入れ替えるにすると、もっと理解しがたい挙動になります。
入れ替え後に要素がビューポートからはみ出していてもスクロールシフトしない
大きめの要素をすぐしたの要素と入れ替えます。入れ替え後に要素はビューポートの下のほうにわずかに見えるばかりですがスクロール調整は起こりません。
https://todays-mitsui.github.io/swap-element-lab/?height=500&scroll=2000&direction=down
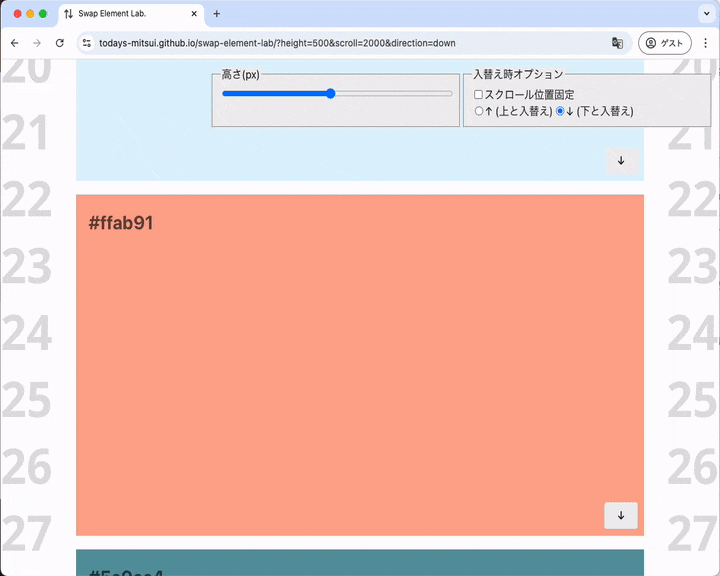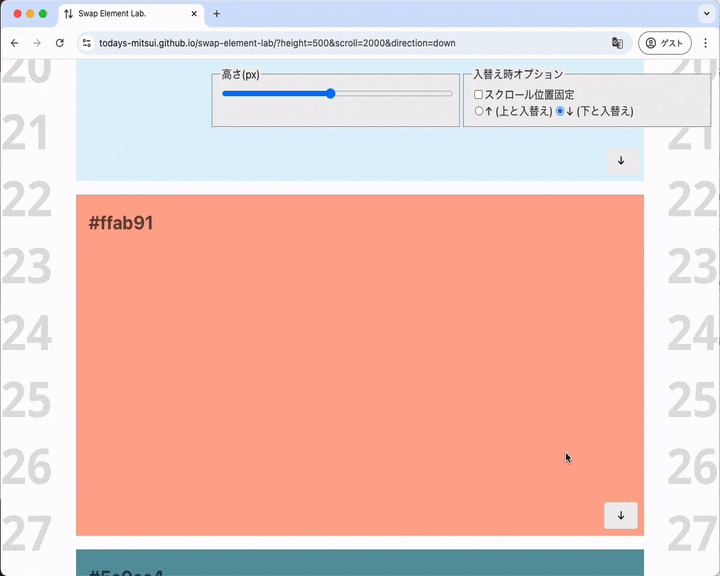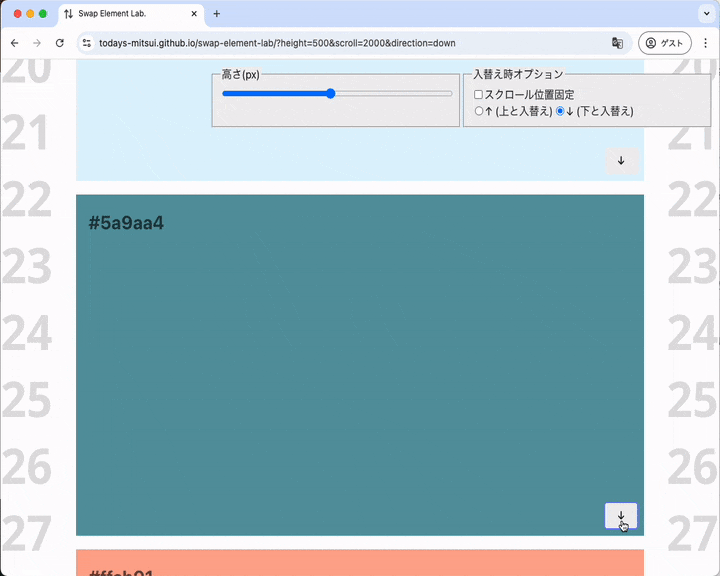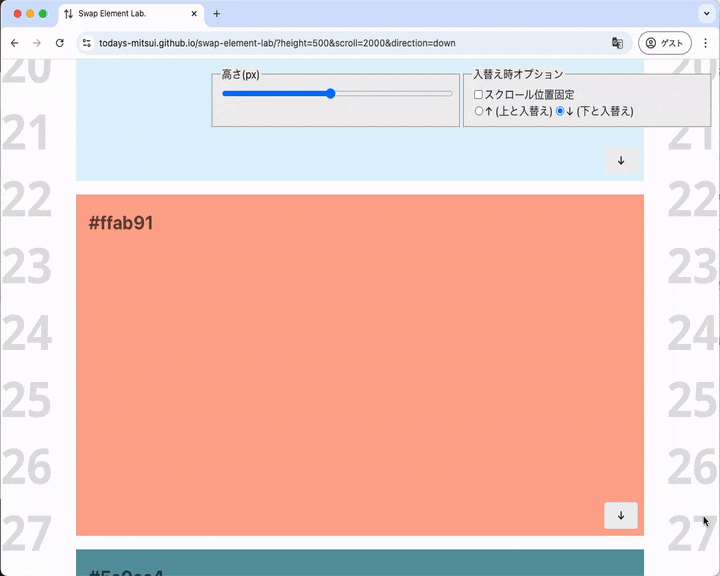 入れ替え後に要素がビューポート下部に置かれるがレイアウトは調整されない
入れ替え後に要素がビューポート下部に置かれるがレイアウトは調整されない
スクロールシフトの結果、要素が下のほうに吹っ飛ぶ
元の要素を見失ってしまいそうなスクロールシフトが起こることもあります。
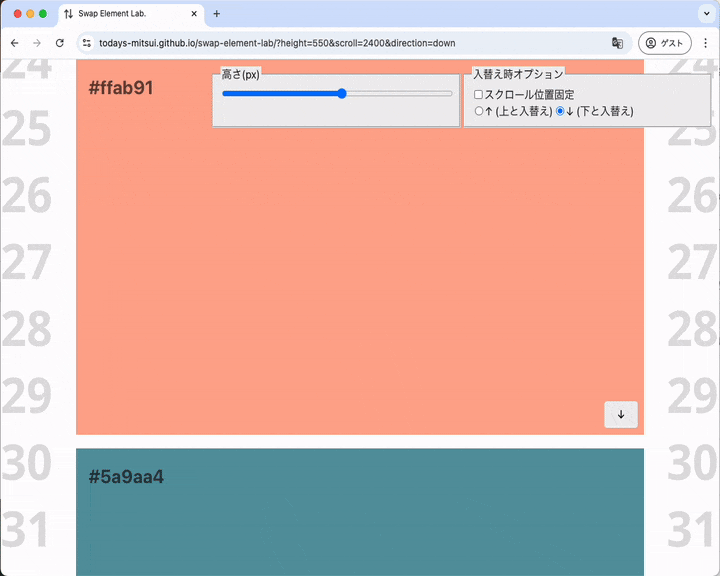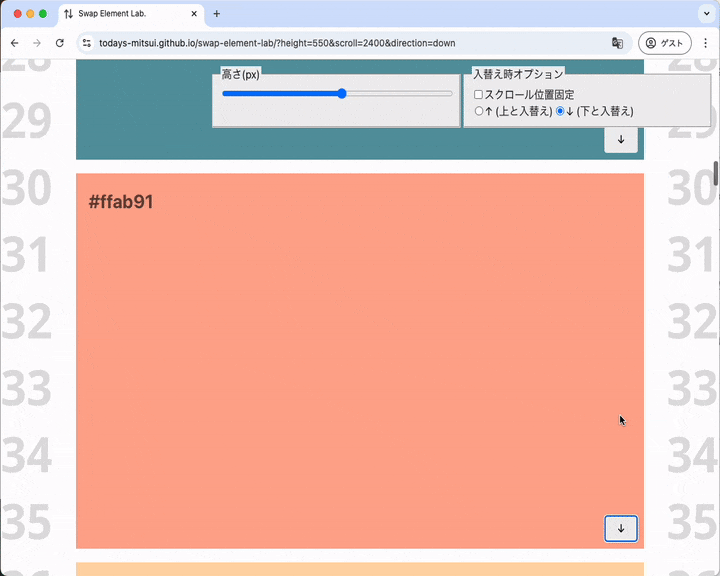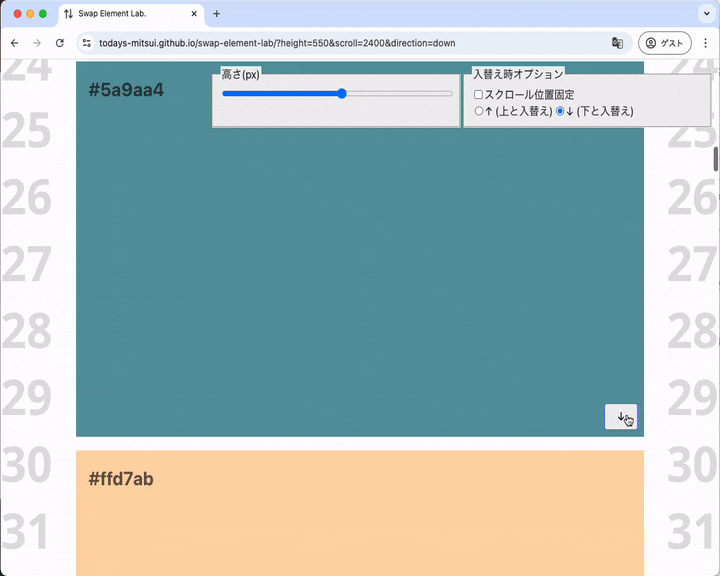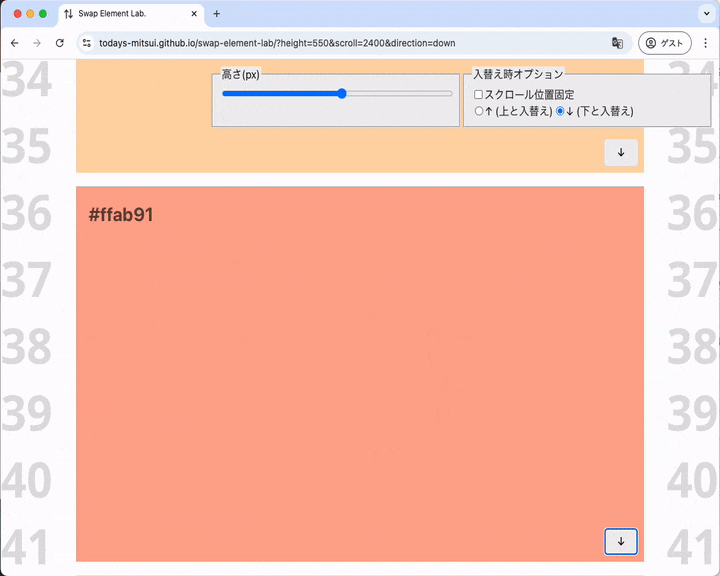 元の要素がビューポートより下に吹っ飛んでいるように見える
元の要素がビューポートより下に吹っ飛んでいるように見える
整理します。
- 入れ替えられた2要素のうち、入れ替え後に上にあるものに着目する
- 上の要素の上端がビューポートの上端に近ければ、ビューポートに充分におさまるように下にスクロール調整する
- 結果として入れ替え後に下にある要素はより下に移動しビューポートから完全に見えなくなる
スクロール調整 (スクロールアンカリング) を無効にする方法
このような挙動は スクロールアンカリング という機能によるものだそうです。この挙動を無効にする方法があります。
CSS の overflow-anchor プロパティ を使います。{ overflow-anchor: none; } を指定した要素は入れ替えによって位置が変わってもスクロール調整の対象になりません。
function App() {
const [colors, setColors] = useState(['#ff6e61', '#4a8a98', '#fff2c2', ...]);
return (
<>
{colors.map((color, index) => (
- <div style={{ backgroundColor: color }} key={color}>
- <div style={{ backgroundColor: color, overflowAnchor: "none" }} key={color}>
<h3>{color}</h3>
<button type="button">↑</button>
</div>
))}
</>
);
}
※ コード例示の都合で style タグを使っています。普通に CSS で設定すれば OK です
今回のデモでは「スクロール位置固定」というオプションに ✅ を入れることでこの挙動を体験できます。
https://todays-mitsui.github.io/swap-element-lab/?height=550&scroll=6000&fixed=true
まとめ
- 入れ替えられた2要素のうち、入れ替え後に上にあるものに着目する
- 上の要素の上端がビューポートの上端に近ければスクロール調整されることがある
- overflow-anchor プロパティでこの挙動を無効化することは可能
こんな感じかなー。たぶん。
この記事の公開後すぐに id:nanto_vi さんから「それってスクロールアンカリングの影響では?」と情報をもらったので スクロール調整 (スクロールアンカリング) を無効にする方法 セクションを加筆修正しました。ズバリの情報ありがとうございました。
私からは以上です。









